
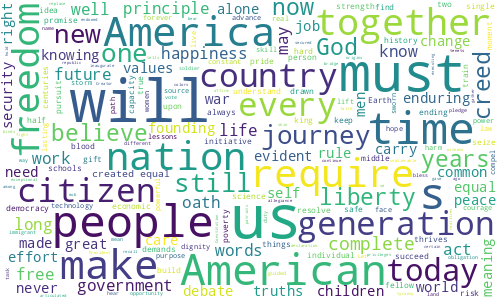
WordCloudをご存じでしょうか。
タイトルにある画像がWordCloudの出力結果で、こちらはオバマ大統領の演説内容をWordCloud化してみた結果です。単語の出現頻度などを考慮して、文章内で重要と推測される単語を強調して表示、表現することができます。
Pythonでは専用のパッケージが用意されていますのですぐに利用することができます。
wordcloudパッケージをインストール
Pythonにwordcloudをインストールします。pipコマンドで簡単にインストールできます。
例によってConoHa Wing環境のPythonにインストールしていますので–userを指定していますが、必須ではありません。
$ pip install --user wordcloud
Collecting wordcloud
Downloading wordcloud-1.8.1-cp36-cp36m-manylinux1_x86_64.whl (366 kB)
|################################| 366 kB 2.9 MB/s
Collecting pillow
Downloading Pillow-8.4.0-cp36-cp36m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (3.1 MB)
|################################| 3.1 MB 60.1 MB/s
Collecting matplotlib
Downloading matplotlib-3.3.4-cp36-cp36m-manylinux1_x86_64.whl (11.5 MB)
|################################| 11.5 MB 81.6 MB/s
Collecting numpy>=1.6.1
Downloading numpy-1.19.5-cp36-cp36m-manylinux2010_x86_64.whl (14.8 MB)
|################################| 14.8 MB 62.3 MB/s
Collecting pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.3
Downloading pyparsing-2.4.7-py2.py3-none-any.whl (67 kB)
|################################| 67 kB 26.0 MB/s
Collecting kiwisolver>=1.0.1
Downloading kiwisolver-1.3.1-cp36-cp36m-manylinux1_x86_64.whl (1.1 MB)
|################################| 1.1 MB 61.3 MB/s
Collecting python-dateutil>=2.1
Downloading python_dateutil-2.8.2-py2.py3-none-any.whl (247 kB)
|################################| 247 kB 58.0 MB/s
Collecting cycler>=0.10
Downloading cycler-0.10.0-py2.py3-none-any.whl (6.5 kB)
Collecting six>=1.5
Downloading six-1.16.0-py2.py3-none-any.whl (11 kB)
Installing collected packages: pillow, numpy, pyparsing, kiwisolver, six, python-dateutil, cycler, matplotlib, wordcloud
Successfully installed cycler-0.10.0 kiwisolver-1.3.1 matplotlib-3.3.4 numpy-1.19.5 pillow-8.4.0 pyparsing-2.4.7 python-dateutil-2.8.2 six-1.16.0 wordcloud-1.8.1
$ wordcloudを実行してみる
WordCloud化する文章を事前にテキストファイルで用意しておきます。ここでは、例として「obama.txt」にオバマ大統領演説の英文を保存しています。こちらから拝借しました。
$ ls -l
:
-rw-r--r-- 1 c9320144 c9320144 12004 Oct 19 21:24 obama.txt
$ python
Python 3.6.11 (default, Aug 11 2020, 06:48:17)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-39)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from wordcloud import WordCloud
>>> text = open("obama.txt", encoding="utf8").read()
>>> wordcloud = WordCloud(width=500, height=300, background_color='white', max_font_size=60).generate(text)
>>> wordcloud.to_file("obama.png")
<wordcloud.wordcloud.WordCloud object at 0x7f2248391780>
>>>
$ ls -l
:
-rw-r--r-- 1 c9320144 c9320144 70163 Oct 19 21:27 obama.png
-rw-r--r-- 1 c9320144 c9320144 12004 Oct 19 21:24 obama.txt実際のコードはこの4行だけです。実行するとobama.txtを読み込んで、結果としてobama.png(タイトル画像)が作成されます。
日本語表示
このままの状態では日本語フォントに対応できていませんので、表示しようとすると文字化けが発生します。正しく日本語フォントを指定してあげることで日本語も表示できるようになります。
日本語フォントをダウンロード
ありがたいことに商用でも利用可能なフリーの日本語フォントがたくさん存在します。自分の好みのフォントを見つけてみてください。
ここでは「Rounded M+」フォントを利用します。フォントをダウンロードして利用したいファイル(*.ttf)をサーバにアップロードしておきます。
MeCabを利用して日本語文章の分割
日本語の場合、単純に日本語の文章を読み込ませても、勝手に単語を認識してくれるわけではありませんので、
期待したWord Cloudを生成できません。
このためMeCabを利用して日本語文章を品詞毎に分割します。
WordCloudでは、日本語文章をスペース区切りの単語の羅列にして読み込ませる必要がありますので、
手動で分割するのは大変です。
MeCabを利用すると、こんな感じで「wagahaiwa_nekodearu_text.txt」に保存された日本語文章を分割できます。
MeCabの使い方はこちらを参照ください。

word_list = []
with open('./wagahaiwa_nekodearu_text.txt', 'r', encoding='utf-8') as f:
for line in f:
node = mecab.parseToNode(line)
while node:
word = node.surface
if word != '':
word_list.append(word)
node = node.next
print(' '.join(word_list))出力結果はこのようになります。
吾輩 は 猫 で ある 。 名前 は まだ 無い 。 どこ で 生れ た か とんと 見当 が つか ぬ 。 何 でも 薄暗い じめじめ し た 所 で ニャーニャー 泣い て いた事 だけ は 記憶 し て いる 。 吾輩 は ここ で 始め て 人間 という もの を 見 た 。
:本来は名詞のみにするといった工夫は必要ですが、まずは単純に分割した結果でWord Cloudを作成してみます。
WordCloudの日本語化
実は日本語表示は非常に簡単で、WordCloud関数の引数font_pathに使用したい日本語フォントファイルのパスを指定してあげるだけです。
import MeCab
from wordcloud import WordCloud
mecab = MeCab.Tagger('-Ochasen')
word_list = []
with open('./wagahaiwa_nekodearu_text.txt', 'r', encoding='utf-8') as f:
for line in f:
node = mecab.parseToNode(line)
while node:
word = node.surface
if word != '':
word_list.append(word)
node = node.next
FONT_PATH='./rounded-mplus-1c-medium.ttf'
wordcloud = WordCloud(font_path=FONT_PATH, width=500, height=300, background_color='white', max_font_size=60).generate(' '.join(word_list))
wordcloud.to_file('./wagahai.png')これで日本語フォントが読み込まれ、日本語が正しく表示されます。

おまけ
今回サンプルの日本語文章に青空文庫の「吾輩は猫である」を拝借していますが、ダウンロード可能なテキストファイルには解析する上で不要なルビなどが含まれています。
以下の正規表現を使ってこれらのパターンにマッチした不要な文字列を削除しました。
《[^》]*》
[#[^]]*]
|

コメント
[…] […]
[…] […]
[…] […]