
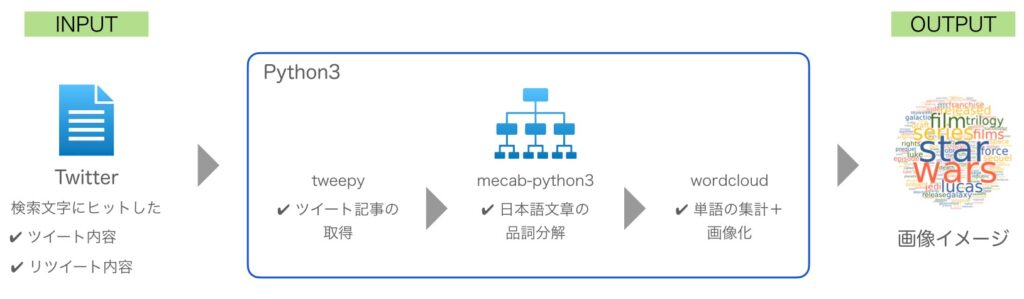
Twitterからの検索結果を利用してWord Cloudを自動生成するプログラムを作成しました。
- INPUT:検索ワード
- OUTPUT:Word Cloud(画像イメージ)
この記事ではPythonを使っていますが、もちろん他のプログラミング言語でも実現できます。言語によって利用できるパッケージが異なりますので、その点は読み替えてください。
Twitterからの情報取得
まずはTwitter上で検索ワードを指定して、ツイートやリツイートを取得します。
Pythonではtweepyパッケージを利用して情報を取得することができます。

日本語文章の分析
得られた検索結果には英語文章だけでなく、日本語文章も含まれます。Word Cloudの生成には日本語文章を分析して単語毎に分けてあげる必要があります。
PythonではMeCabパッケージを利用できます。
絵文字除去
日本語を扱うにあたって絵文字が邪魔なので排除します。Pythonには絵文字を扱うためのemojiパッケージが存在しており、簡単に絵文字を除去することができます。
emojiパッケージをインストールします。
$ pip install emoji絵文字の除去にはreplace_emoji関数を利用することができます。具体的には以下のようなコードで、絵文字を空文字(‘’)に置き換えています。
>>> import emoji
>>> str
'日中はPythonの勉強😊\n\n今日を楽しみましょう☺\n\n'
>>>
>>> emoji.replace_emoji(str, '')
'日中はPythonの勉強\n\n今日を楽しみましょう\n\n'
>>>Twitterアカウント情報などの除去
ツイート内容には@で始まるTwitterアカウントやURLなどの日本語を分析する上で扱いづらい文字列が存在します。ここではTwitterアカウントなどは考慮しないように除去したいと思います。(ハッシュタグはあえて含めています)
正規表現を扱うreパッケージを利用して不要な文字列を排除します。かなり大雑把ですが、以下で不要な文字列を除去できます。
>>> import re
# URL除去
>>> re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-]+', '', str)
# Twitterアカウント除去
>>> re.sub(r'@.+ ', '', str)
# リツート用の「RT」文字列除去
>>> re.sub(r'RT ', '', str)
# 「#」や「?」が名詞として扱われてしまうため半角スペースに置換
>>> re.sub(r'#|\?|?', ' ', str)
# 数字は名詞として扱われてしまうため半角スペースに置換
>>> re.sub(r'\d+', ' ', str)不要な文字列の除去ができたら、MeCabパッケージを利用して日本語文章を分析していきます。
Word Cloud化
最後に分析した日本語文章をWord Cloud化して画像イメージを生成します。
Pythonではwordcloudパッケージを利用できます。

Pythonコード
参考までに今回のPythonプログラムのコードを載せておきます。上手く動かないなどあれば教えてください。
import emoji
import MeCab
import numpy as np
import re
import tweepy
from wordcloud import WordCloud
API_KEY = '**********'
API_SECRET = '**********'
ACCESS_TOKEN = '**********'
ACCESS_TOKEN_SECRET = '**********'
FONT_PATH='./rounded-mplus-1c-medium.ttf'
OUTPUT_PATH='./twitter_wc.png'
mecab = MeCab.Tagger('-Ochasen')
x, y = np.ogrid[:600, :600]
mask = (x - 300) ** 2 + (y - 300) ** 2 > 260 ** 2
mask = 255 * mask.astype(int)
auth = tweepy.OAuthHandler(API_KEY, API_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET)
api = tweepy.API(auth)
word_list = []
qstr = input('検索ワード:')
for tweet in tweepy.Cursor(api.search_tweets, q=qstr, lang='ja').items(100):
ss = emoji.replace_emoji(tweet.text, '')
ss = re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-]+', '', ss)
ss = re.sub(r'@.+ ', '', ss)
ss = re.sub(r'RT ', '', ss)
ss = re.sub(r'#|\?|?', ' ', ss)
ss = re.sub(r'\d+', ' ', ss)
node = mecab.parseToNode(ss)
while node:
word_type = node.feature.split(",")[0]
word = node.surface
if word != '' and word_type in ['形容詞','名詞','副詞']:
word_list.append(word)
node = node.next
wordcloud = WordCloud(font_path=FONT_PATH, width=500, height=300, background_color='white', max_font_size=80, mask=mask, min_font_size=2, max_words=500).generate(' '.join(word_list))
wordcloud.to_file(OUTPUT_PATH)
print('出力画像イメージ:%s' % OUTPUT_PATH)実行結果は以下の通りで、検索ワードを入力させるようにしています。
$ python tw_wc.py
検索ワード:python
出力画像イメージ:./twitter_wc.png
$このようなWord Cloudの画像イメージが生成されます。

Twitterは常に更新されていますので、プログラムを実行する度に異なるWord Cloudになります。今のトレンドを追っかけていくのも面白そうですね。


コメント