

LLMによる回答の精度を上げる手法として、ファインチューニングやRAGがあります。
本記事では、実際にRAGを使う手順とRAGを使った場合と使わない場合の比較結果をまとめています。
こちらも比較的簡単にRAGを使うことができます。
本記事は、[Python] ローカルLLMをできるだけシンプルに使ってみるの続きとしてまとめています。

RAGって何?
RAG(Retrieval-Augmented Generation)とは、「情報検索(Retrieval)」と「テキスト生成(Generation)」を組み合わせたハイブリッド型のAIアーキテクチャです。
通常のLLM(Large Language Model:大規模言語モデル)では、あくまで「学習済みの知識」に基づいて回答を生成しますが、RAGを使うことで、外部データベースから必要な情報をリアルタイムで取得して回答を生成することができます。
回答の精度を高められる仕組みと考えてください。
回答の精度を高める仕組みとして「ファインチューニング」も有名です。
こちらはLLMに対して必要な情報を学習させ、「学習済みの知識」を増やすことにフォーカスした手法です。
RAGもファインチューニングも目的は同じですが、最近は学習コストなどの観点からRAGに注目が集まっています。
RAGを利用するための準備
本記事ではPythonでRAGを利用するためにいくつかのパッケージをインストールします。
Pythonバージョンは3.13.0を使っています。
- Ollama:Ollama(LLMを利用するためのフレームワーク)を使うためのパッケージ。「
pip install ollama」コマンドでインストール可能。こちらの記事を参照ください。 - LangChain:RAGを利用するためのフレームワークパッケージ。
- ChromaDB:ベクトルDB用パッケージ。RAGの情報ソースの格納先としてのベクトルDBを使うために必要です。
- PyPDF:PythonでPDBを扱うためのパッケージ。今回はPDBを情報ソースとして使用するために必要です。
(必要に応じて)Microsoft Visual C++をインストール
Windows環境でLangChainパッケージやChromaDBパッケージをインストールする際に、「Microsoft Visual C++ 14.0 or greater is required」といったエラーが発生する場合があります。
× Building wheel for chroma-hnswlib (pyproject.toml) did not run successfully.
│ exit code: 1
╰─> [5 lines of output]
running bdist_wheel
running build
running build_ext
building 'hnswlib' extension
error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/
[end of output]本エラーが発生した場合は、以下の手順でMicrosoft Visual C++をインストールします。

「vs_BuildTools.exe」ファイルがダウンロードされると思いますので、ファイルを実行します。
Visual Studio Installerが起動しますので、「続行」をクリックします。
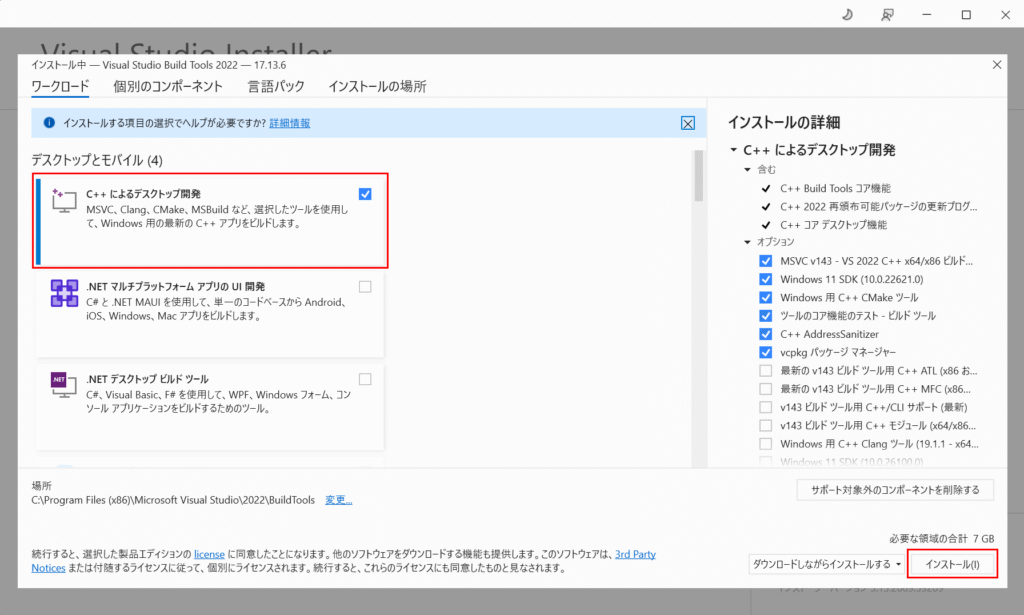
インストールする項目一覧が表示されますので、「C++によるデスクトップ開発」にチェックを入れ、「インストール」を選択します。
インストールが開始されます。
インストールが完了するとインストール済みの項目として「Visual Studio Build Tools 2022」が表示されます。
LangChainとChromaDBパッケージをインストール
「pip install langchain langchain_community langchain_ollama langchain_chroma」コマンドを使用して、LangChainパッケージとChromaDBを含む関連パッケージをインストールします。
PS C:\Users\XXXXXXXX> pip install langchain langchain_community langchain_ollama langchain_chroma
Collecting langchain
Using cached langchain-0.3.24-py3-none-any.whl.metadata (7.8 kB)
Collecting langchain_community
Using cached langchain_community-0.3.22-py3-none-any.whl.metadata (2.4 kB)
Collecting langchain_ollama
Using cached langchain_ollama-0.3.2-py3-none-any.whl.metadata (1.5 kB)
:
Successfully built chroma-hnswlib
Installing collected packages: pypika, mpmath, monotonic, ...
PS C:\Users\XXXXXXXX>PyPDFパッケージをインストール
「pip install pypdf」コマンドを使用して、PyPDFパッケージをインストールします。
PS C:\Users\XXXXXXXX> pip install pypdf
Collecting pypdf
Downloading pypdf-5.4.0-py3-none-any.whl.metadata (7.3 kB)
Downloading pypdf-5.4.0-py3-none-any.whl (302 kB)
Installing collected packages: pypdf
Successfully installed pypdf-5.4.0
PS C:\Users\XXXXXXXX>サンプルコード
本記事では「トランプ2.0とは何ですか?」を問い合わせ文として使います。
LLM版
本記事ではOllama経由でGemma2のLLMを使用しますので、事前に使えるようにしておきます。
PS C:\Users\XXXXXXXX> ollama pull gemma2:2b
pulling manifest
pulling 7462734796d6... 100% ▕████████████████████████████████████████████████████▏ 1.6 GB
pulling e0a42594d802... 100% ▕████████████████████████████████████████████████████▏ 358 B
pulling 097a36493f71... 100% ▕████████████████████████████████████████████████████▏ 8.4 KB
pulling 2490e7468436... 100% ▕████████████████████████████████████████████████████▏ 65 B
pulling e18ad7af7efb... 100% ▕████████████████████████████████████████████████████▏ 487 B
verifying sha256 digest
writing manifest
success
PS C:\Users\XXXXXXXX> ollama list
NAME ID SIZE MODIFIED
gemma2:2b 8ccf136fdd52 1.6 GB 9 seconds agoLLMのみを利用したサンプルコードがこちらです。
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="gemma2:2b")
query = "トランプ2.0とは何ですか?"
answer = llm.invoke(query)
print(answer)LLM+RAG版
まずは「トランプ2.0」の内容が書かれた記事をRAGの情報ソースとして利用します。
本記事ではこちらの記事を拝借しました。
WebページをPDFで保存することができますので、比較的簡単に情報ソースを準備することができます。
「trump2.0.pdf」として保存しておきます。
さらにこのPDFをベクトルDBに格納するため、Embedding Model(埋め込みモデル)を指定する必要があります。
Embedding Modelは、テキストや画像、音声などの様々なデータを、コンピュータが扱いやすい数値ベクトルに変換する技術で、目的によって手法も異なりますので様々なEmbedding Modelが存在します。
本記事では「mxbai-embed-large」というEmbedding Modelを使用しています。
こちらもOllama経由で利用しますので、事前に使えるようにしておきます。
PS C:\Users\XXXXXXXX> ollama pull mxbai-embed-large
pulling manifest
pulling 819c2adf5ce6... 100% ▕████████████████████████████████████████████████████▏ 669 MB
pulling c71d239df917... 100% ▕████████████████████████████████████████████████████▏ 11 KB
pulling b837481ff855... 100% ▕████████████████████████████████████████████████████▏ 16 B
pulling 38badd946f91... 100% ▕████████████████████████████████████████████████████▏ 408 B
verifying sha256 digest
writing manifest
success
PS C:\Users\XXXXXXXX> ollama list
NAME ID SIZE MODIFIED
mxbai-embed-large:latest 468836162de7 669 MB 8 seconds ago
gemma2:2b 8ccf136fdd52 1.6 GB 22 hours agoLLMとRAGを利用したサンプルコードです。
from langchain_community.document_loaders import PyPDFLoader
from langchain_chroma import Chroma
from langchain_ollama import OllamaEmbeddings
from langchain_ollama import OllamaLLM
from langchain.indexes import VectorstoreIndexCreator
loader = PyPDFLoader("trump2.0.pdf")
embeddings = OllamaEmbeddings(model="mxbai-embed-large:latest")
llm = OllamaLLM(model="gemma2:2b")
index = VectorstoreIndexCreator(
vectorstore_cls=Chroma,
embedding=embeddings
).from_loaders([loader])
query = "トランプ2.0とは何ですか?"
answer = index.query(query, llm=llm)
print(answer)実行結果比較
それぞれ実行してみた結果を比較してみますと、LLMのみの場合は、過去のトランプ大統領の発言や行動から推測した内容に留まっていることに対して、LLM+RAGでは、外部の追加情報が反映され、具体的な施策の内容などが考慮された回答になっています。
「トランプ2.0」は、アメリカの政治家であるドナルド・トランプの政策や行動を、より具体的に、そしてより正確に表現するために使われる言葉です。
これは、トランプ大統領の政策や行動を、より包括的に捉えるための新しい用語として広く使われています。例えば、トランプ大統領が「アメリカを再び強大にする」という主張を、具体的な政策や行動によって示すために、「トランプ2.0」という言葉が使われることがあります。
ただし、「トランプ2.0」は、必ずしもポジティブな意味合いを持つわけではありません。これは、トランプ大統領の政策や行動に対する批判的な意見を表現する際に使用される言葉でもあります。
より詳細な情報を得るためには、具体的な状況や文脈を確認することが必要です。
トランプ2.0は、ドナルド・トランプ氏が2025年1月20日再選されたことを受け、アメリカ大統領として続行した政策を指します。この政策は、貿易や経済、エネルギーなど、様々な分野で、アメリカ国内の利益を優先する方針に基づいています。
具体的には、減税、関税措置、安全保障強化などが主な政策となっています。また、国際情勢も大きく変化し、世界経済に大きな影響を与えることが予想されています。
まとめ
本記事では、LLMにRAGを適用してみて、実際に回答精度が上がることを確認できました。
今回はかなりシンプルなケースで試してみましたが、RAGとなる情報量を多くしていくことで、より精度の高い回答が得れるかと思います。

コメント